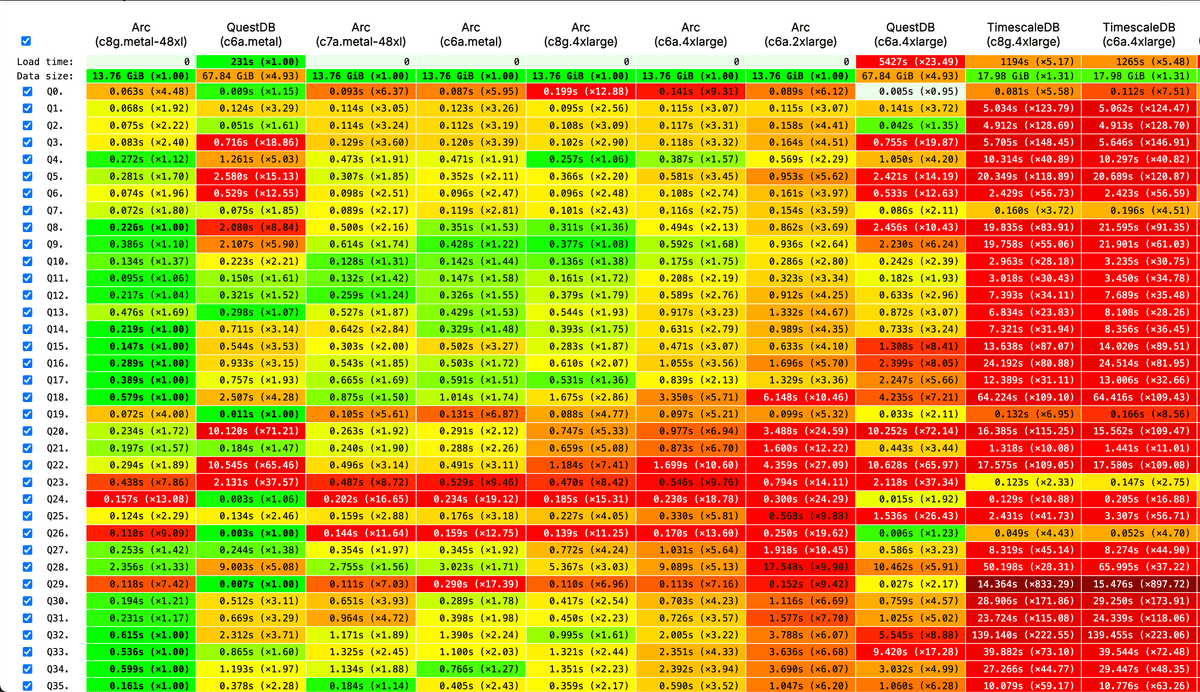
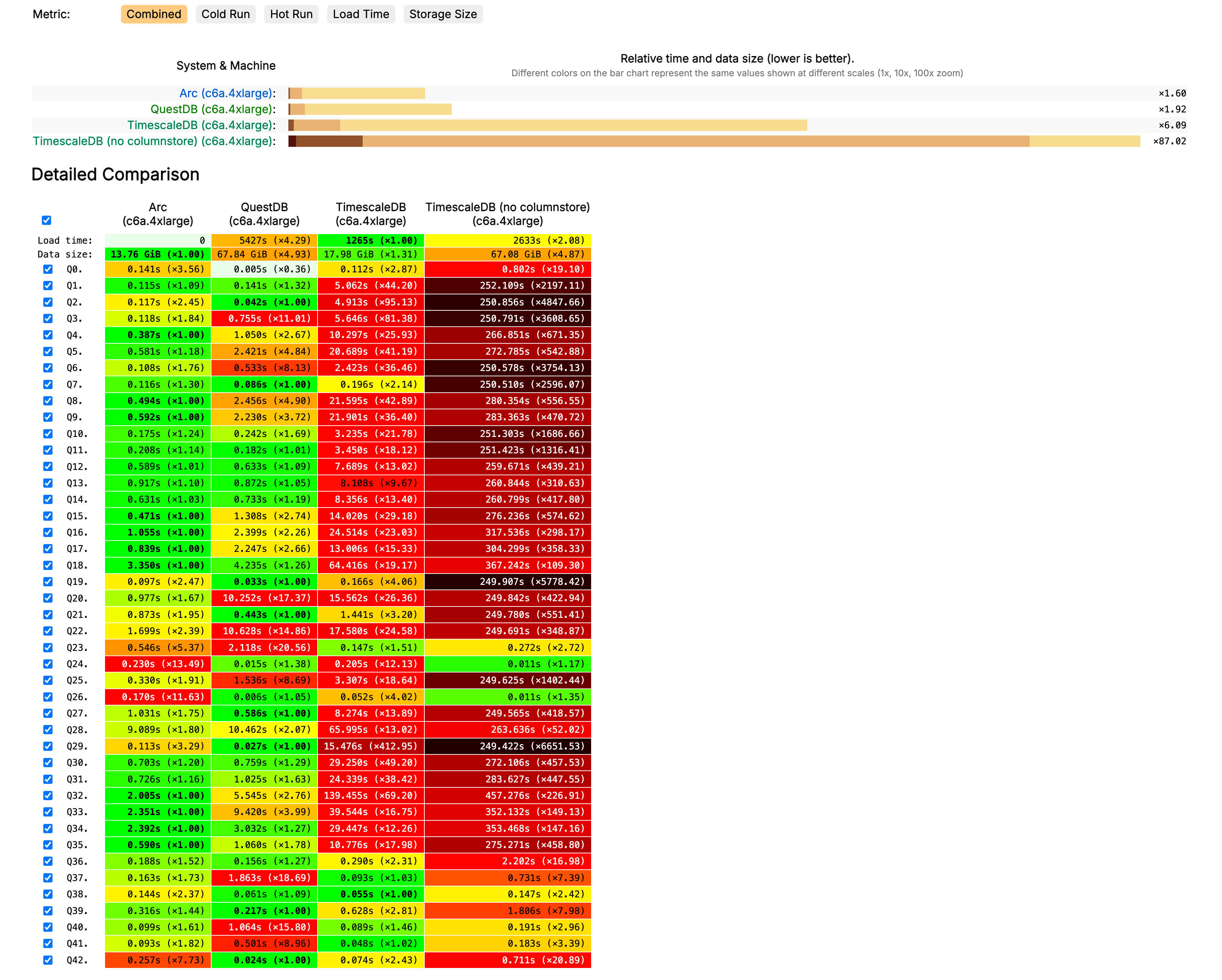
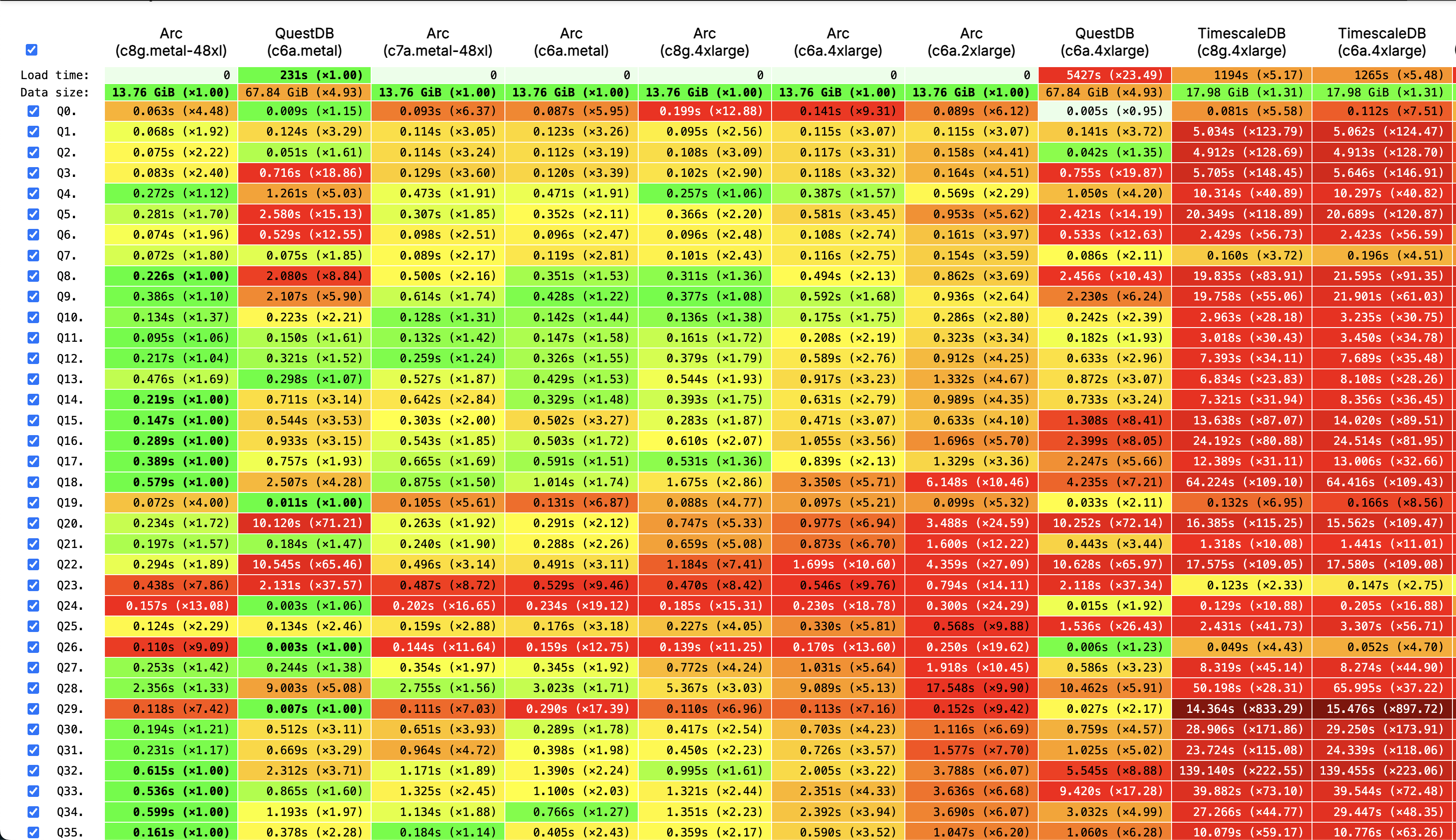
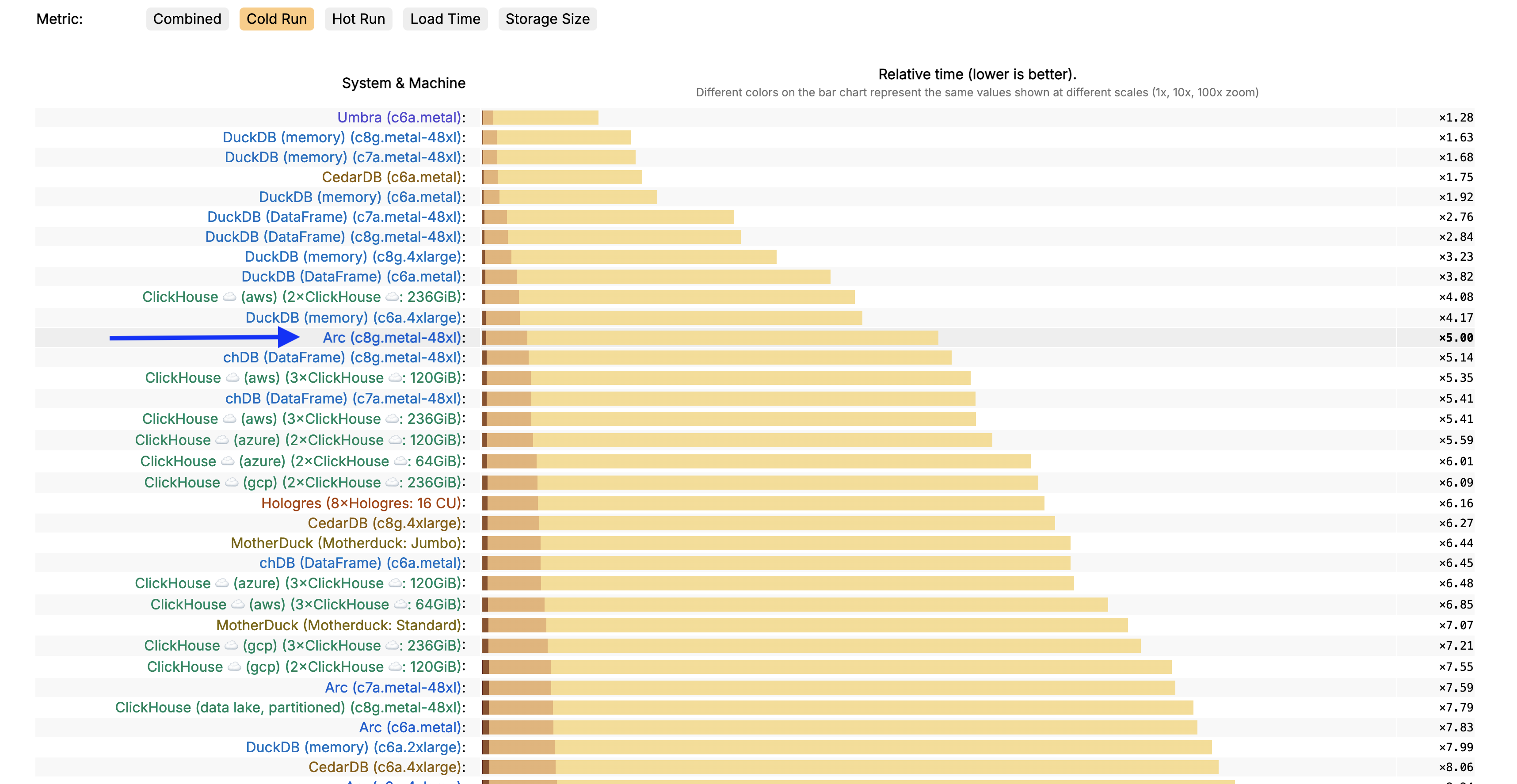
Supercharge Arc with the VS Code Database Manager Extension
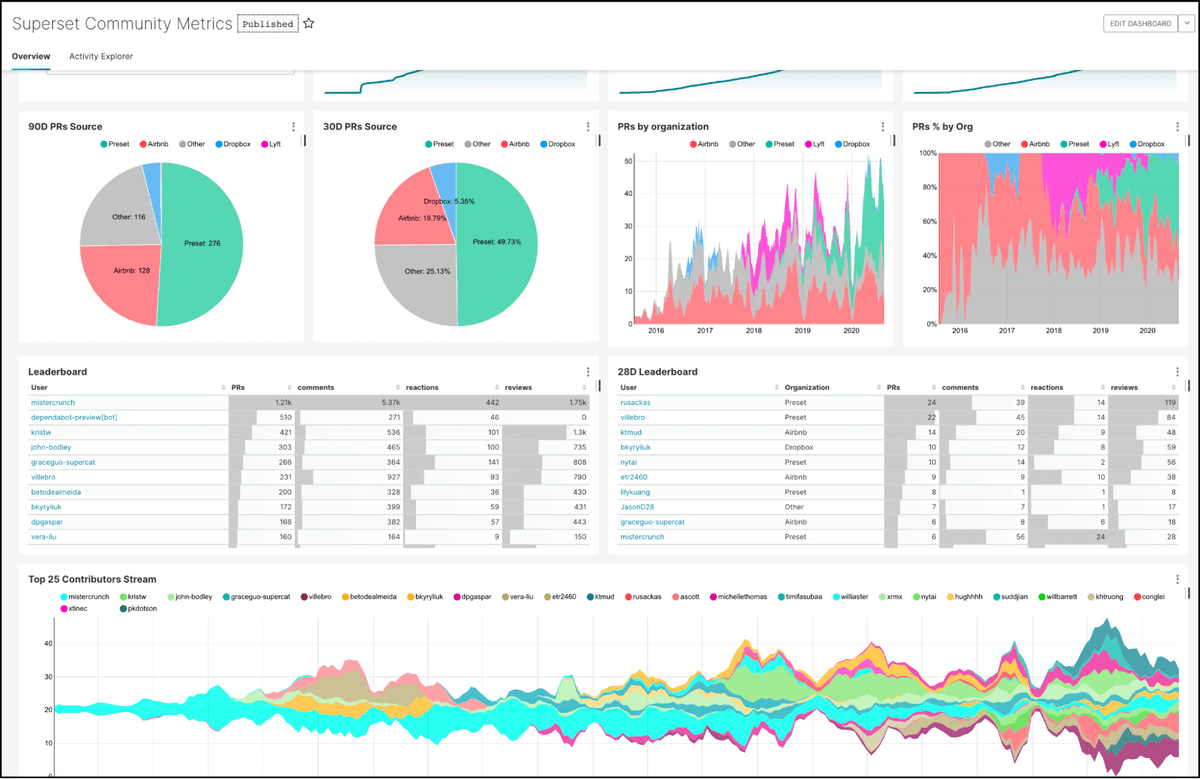
The other day we shared how you can interact with Arc using Apache Superset for visualization. Today we're even more excited to introduce Arc Database Manager, our Visual Studio Code (VS Code, for friends) extension for working with Arc.
While a standalone UI remains on the roadmap, we wanted to give engineers and developers a better way to manage Arc right now—and what better place than one of the most popular IDEs out there?
In this article I'll walk you through the feature set and show you how to get up and running. Ready? Let's go!
Features
Here's what the extension can do today.
Connection Management
- Multiple saved connections with secure token storage
- Quick connection switching
- Connection health monitoring
- Visual status indicators in sidebar and status bar
Query Execution
- SQL IntelliSense with auto-completion for tables, columns, and DuckDB functions
- Execute queries with Ctrl+Enter / Cmd+Enter
- Interactive results view with:
- Export to CSV, JSON, or Markdown
- Automatic chart visualization for time-series data
- Table sorting and filtering
- Execution time and row count statistics
Arc Notebooks
- Mix SQL and Markdown in a single document (.arcnb files)
- Execute cells individually or all at once
- Parameterized queries with variable substitution
- Export notebooks to Markdown with results
- Auto-save functionality
Schema Explorer
- Browse databases and tables in sidebar
- Right-click context menus for:
- Show table schema
- Preview data (first 100 rows)
- Show table statistics
- Generate SELECT queries
- Quick time filters (last hour, today)
Data Ingestion
- CSV Import with guided wizard
- Auto-detect delimiters and headers
- Timestamp column selection
- Batch processing for large files
- Uses high-performance MessagePack columnar format
- Bulk Data Generator with 5 presets:
- CPU Metrics
- Memory Metrics
- Network Metrics
- IoT Sensor Data
- Custom schemas
Alerting & Monitoring
- Create alerts based on query results
- 5 condition types: greater than, less than, equals, not equals, contains
- Configurable check intervals (minimum 10 seconds)
- Desktop notifications when alerts trigger
- Alert history tracking
- Enable/disable alerts without deletion
Query Management
- Automatic query history - every query is logged
- Saved queries - bookmark frequently used queries
- View execution time, row counts, and errors
- Quick re-run from history
Token Management
- Create, rotate, and delete server tokens
- Verify token validity
- Secure storage in system keychain
- Visual token management in sidebar
Dark Mode Support
- Automatic theme detection - adapts to VS Code theme
- Works with Light, Dark, and High Contrast themes
- Theme-aware charts and visualizations
- No configuration needed
As you can see, we're not taking this lightly—ADM (Arc Database Manager) is packed with features, with more already in the works.
Installation
Arc Database Manager is live in the VS Code Marketplace. Search for Arc Database Manager, install it, and enable auto-updates so you're always running the latest release.
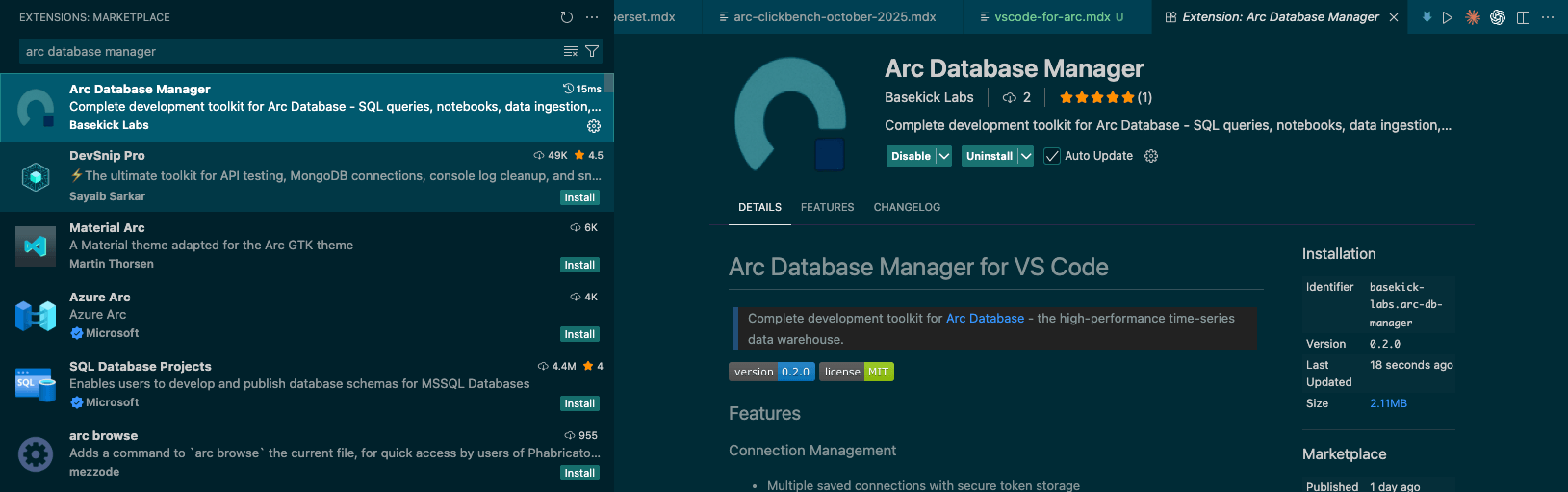
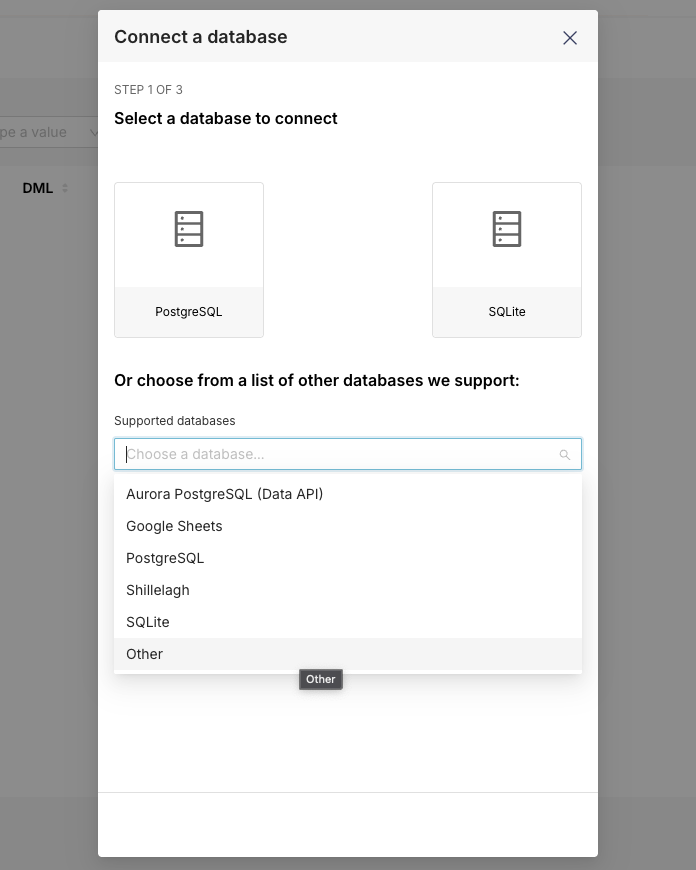
Once it's installed, connect Arc Database Manager to your Arc instance.
Connecting ADM to Arc
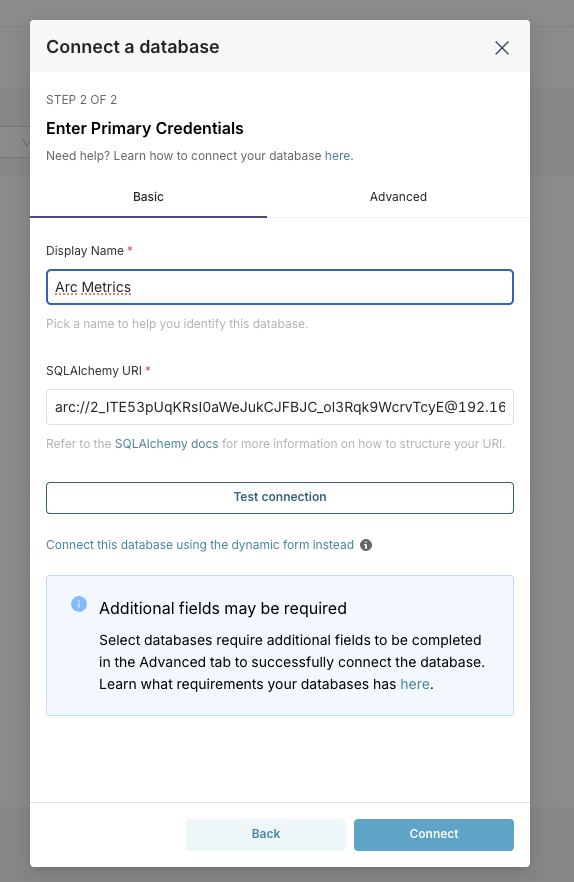
In the status bar (bottom left of VS Code) you'll see Arc: Not connected. Click it to open the command palette and provide:
- Name: Arc Server or any label you prefer
- Host:
http://localhostif Arc is running locally, orhttps://my-arc-serverbehind a reverse proxy - Port:
8000by default, or443for HTTPS - Protocol:
httporhttps - Authentication Token: Grab this from the Arc logs on first run
If everything checks out, your connections list will look something like this.
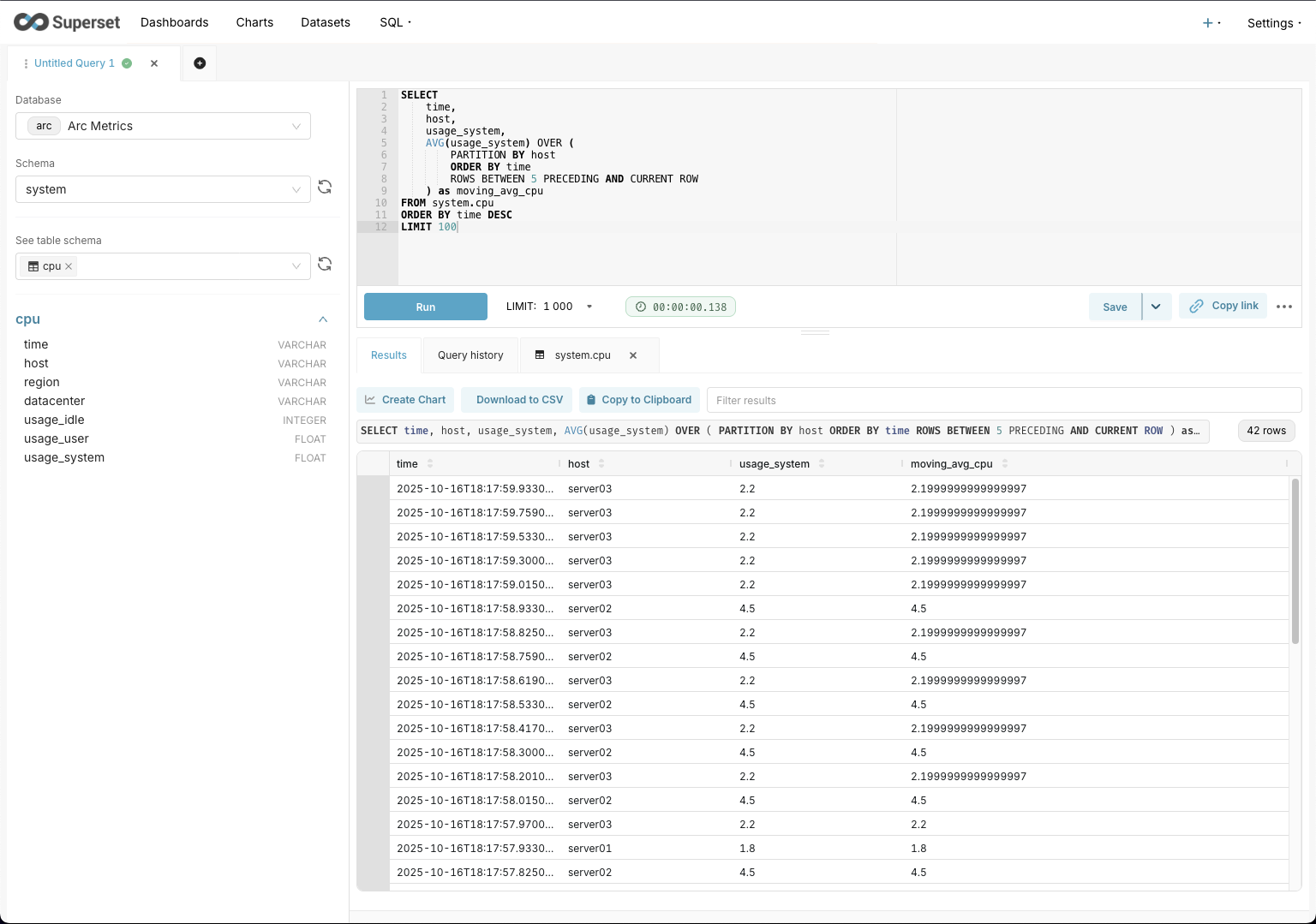
Querying Arc
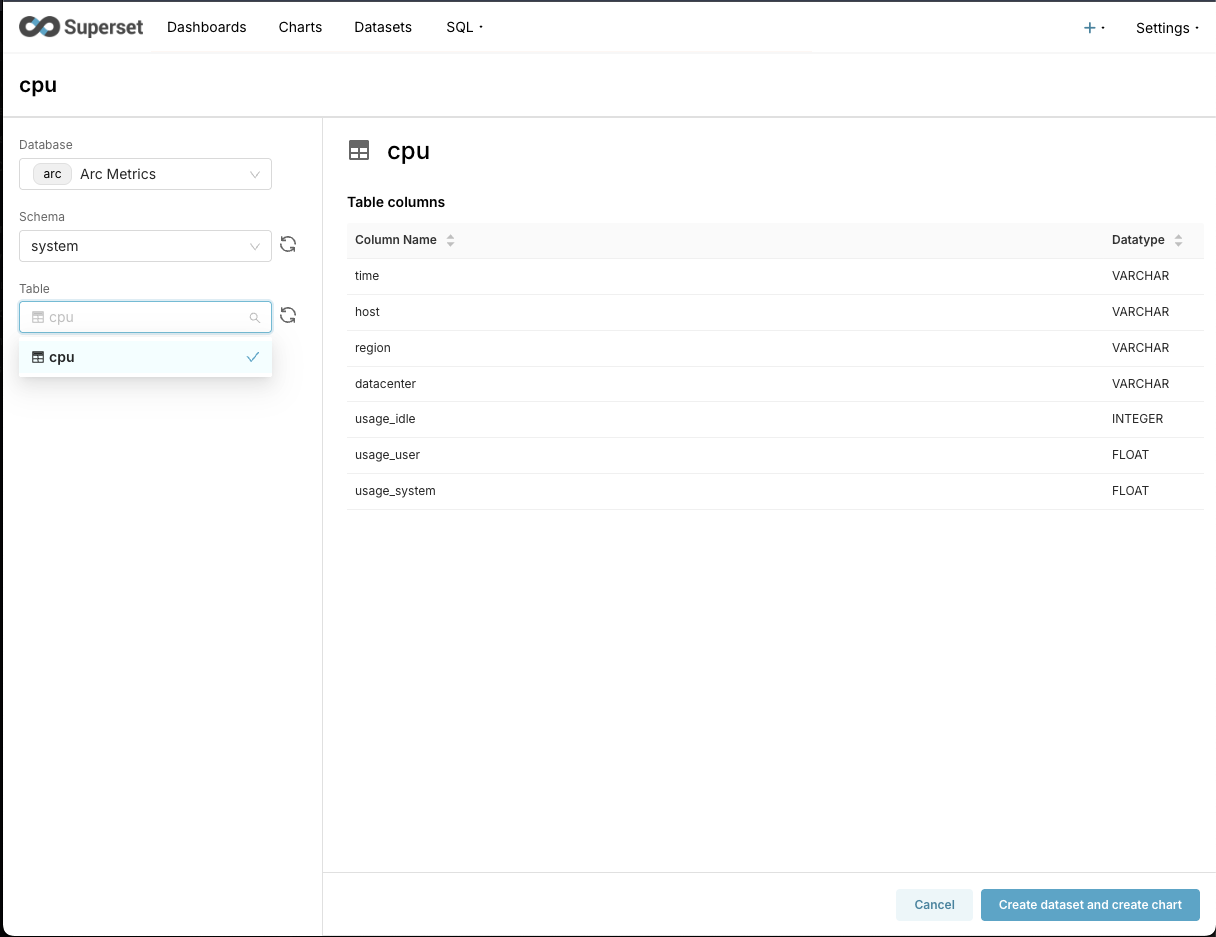
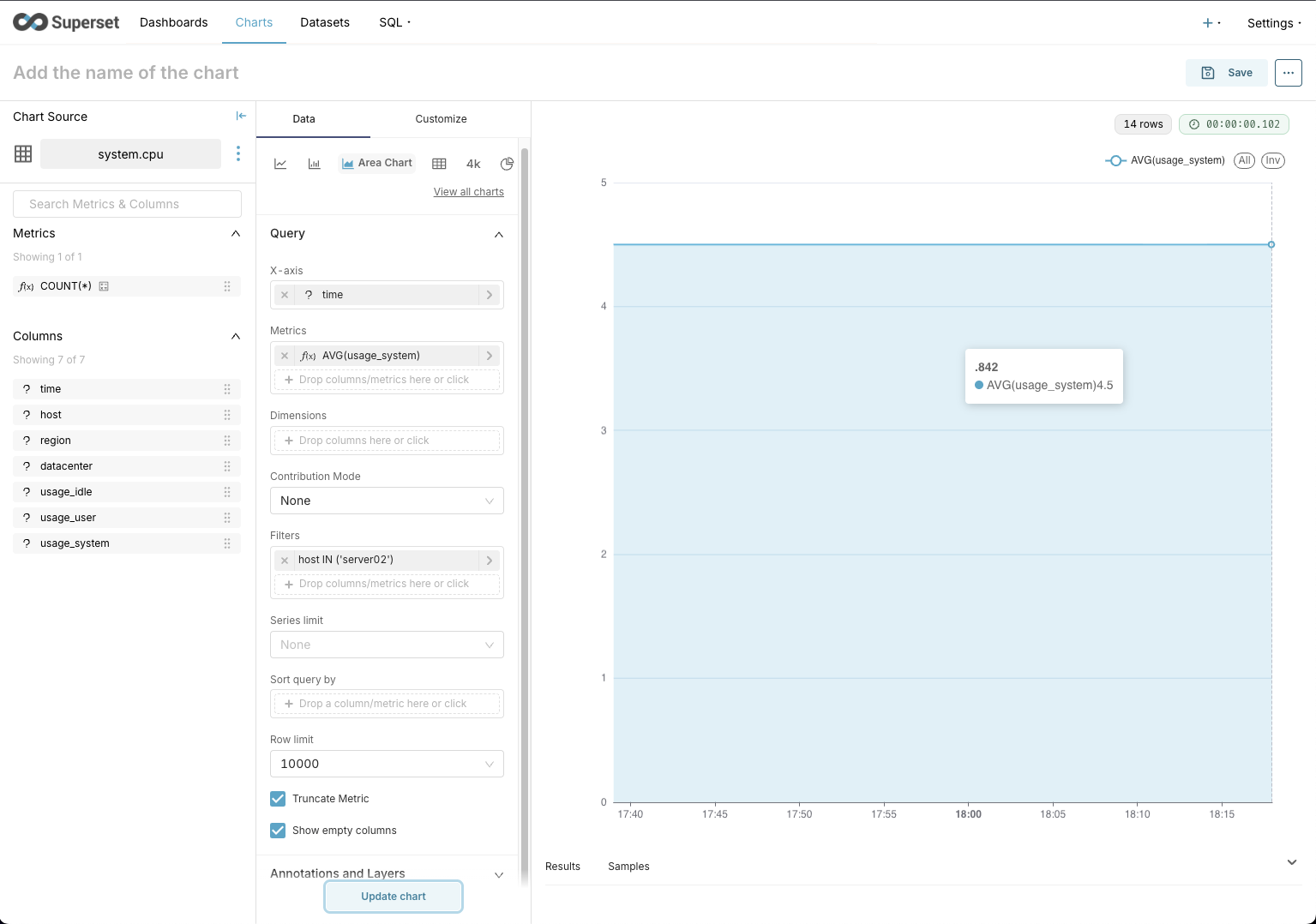
As mentioned earlier, the extension lets you query Arc and browse the schema without leaving your editor.
In this example I used the telegraf database and the cpu measurement/table. (We're working on a native Telegraf integration—stay tuned!)
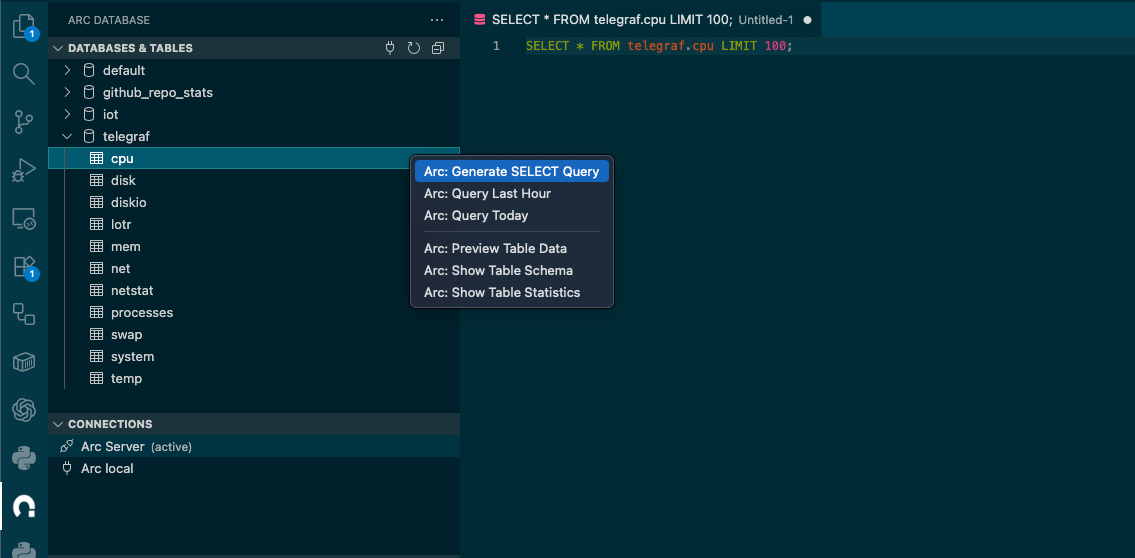
Once the query is ready, execute it with:
- Mac:
Cmd+Enter - Windows/Linux:
Ctrl+Enter
Results open in a new VS Code tab.
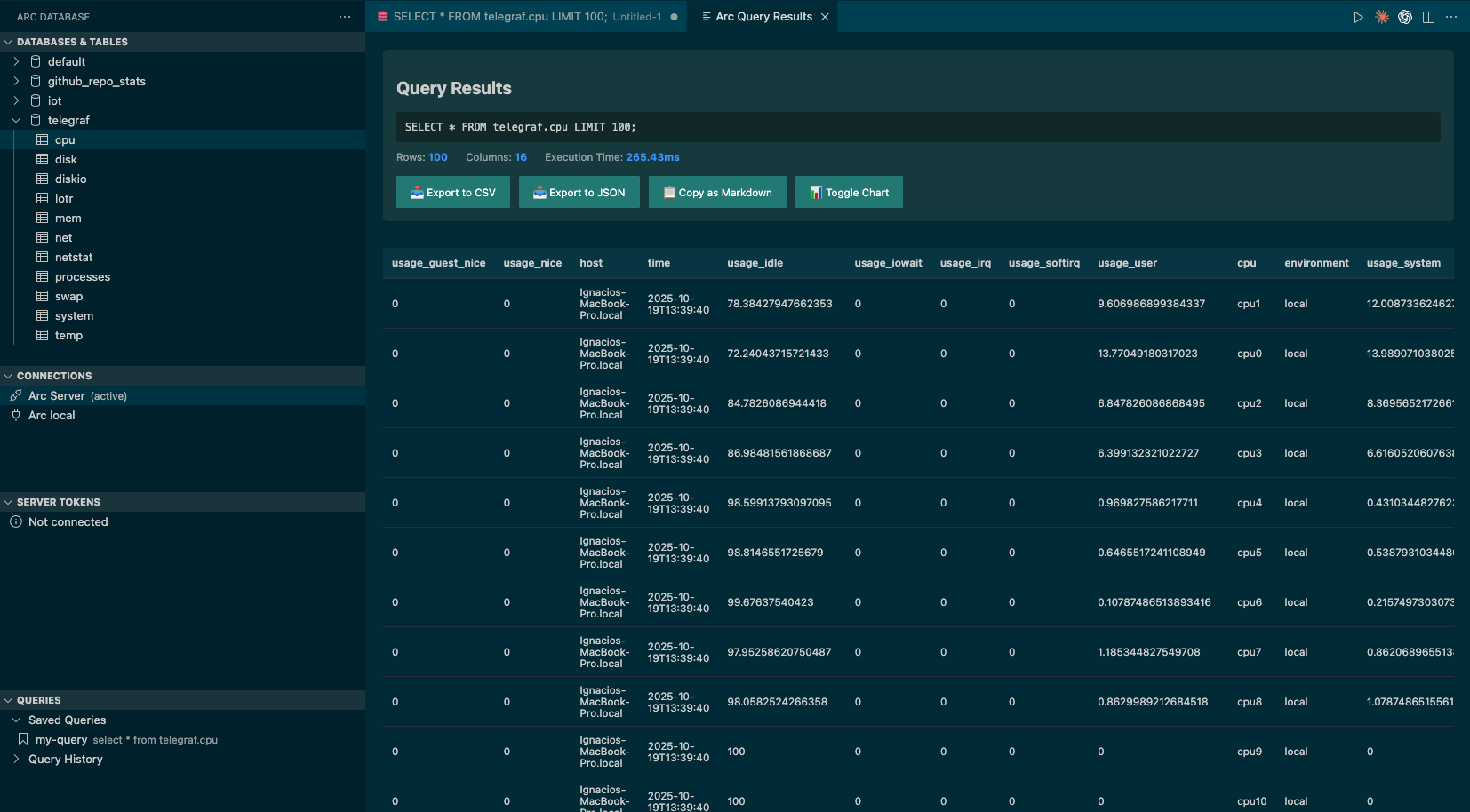
From there you can export to CSV or JSON, copy the results as Markdown, or toggle a chart view—like the one below.
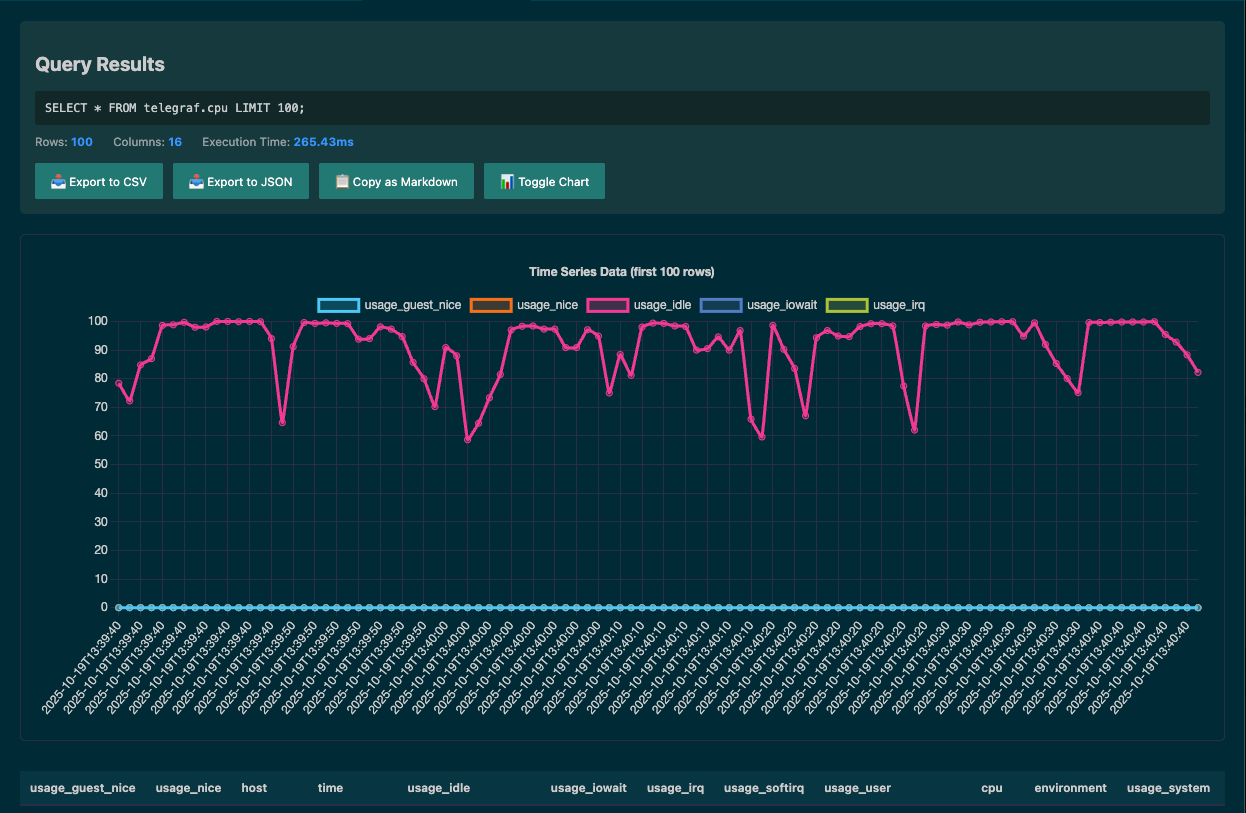
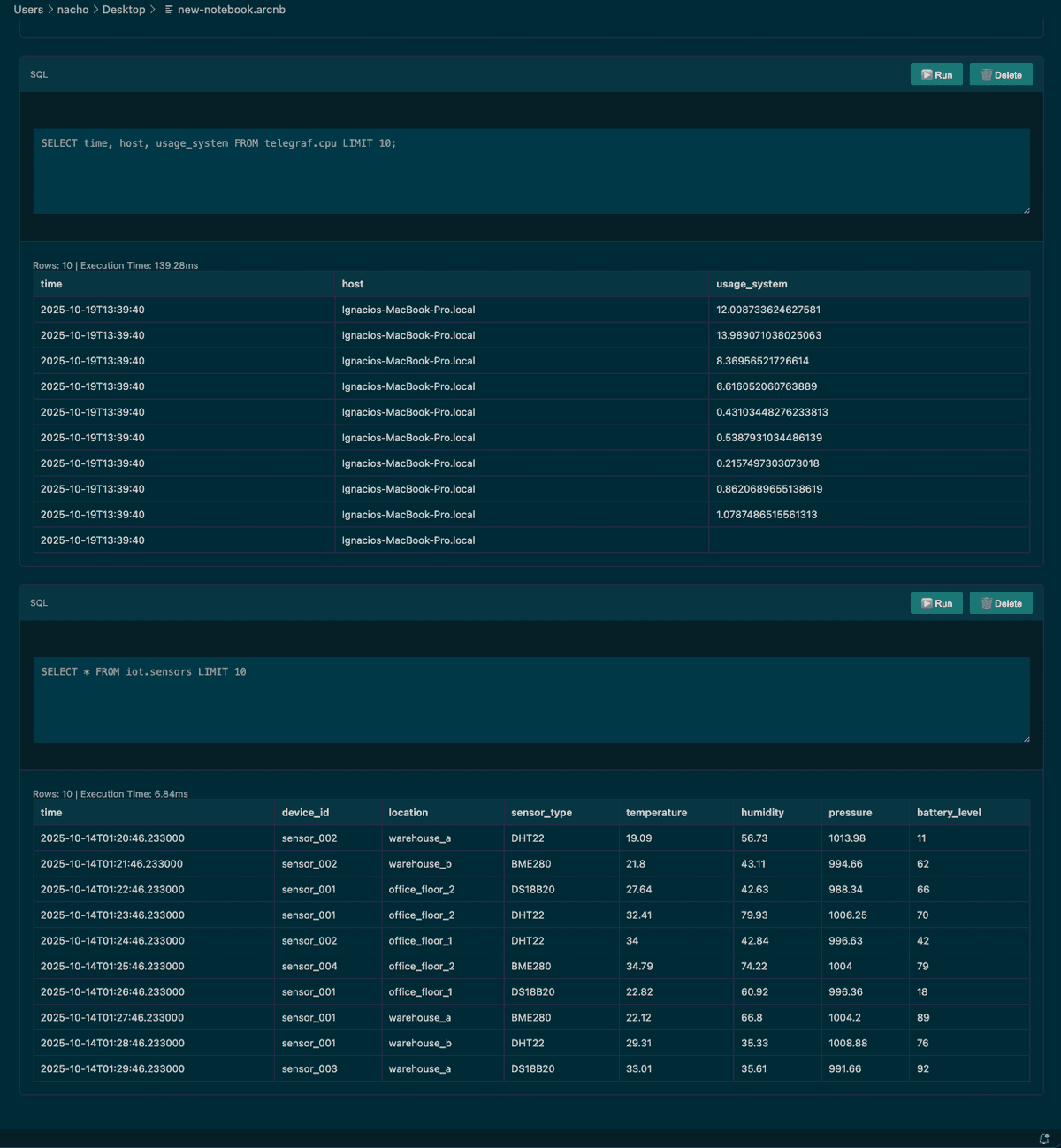
Notebooks
Notebook support was one of the first features I wanted to include—here's how to use it.
Open the command palette (Cmd+Shift+P on macOS, Ctrl+Shift+P on Windows/Linux) and type Arc: New Notebook.
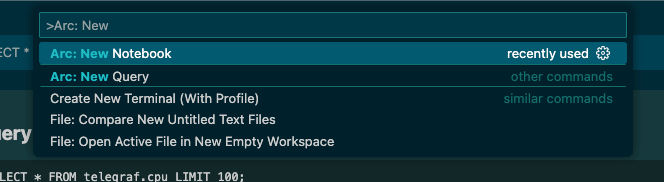
Save the file—I named mine new-notebook.arcnb—and the notebook opens automatically.
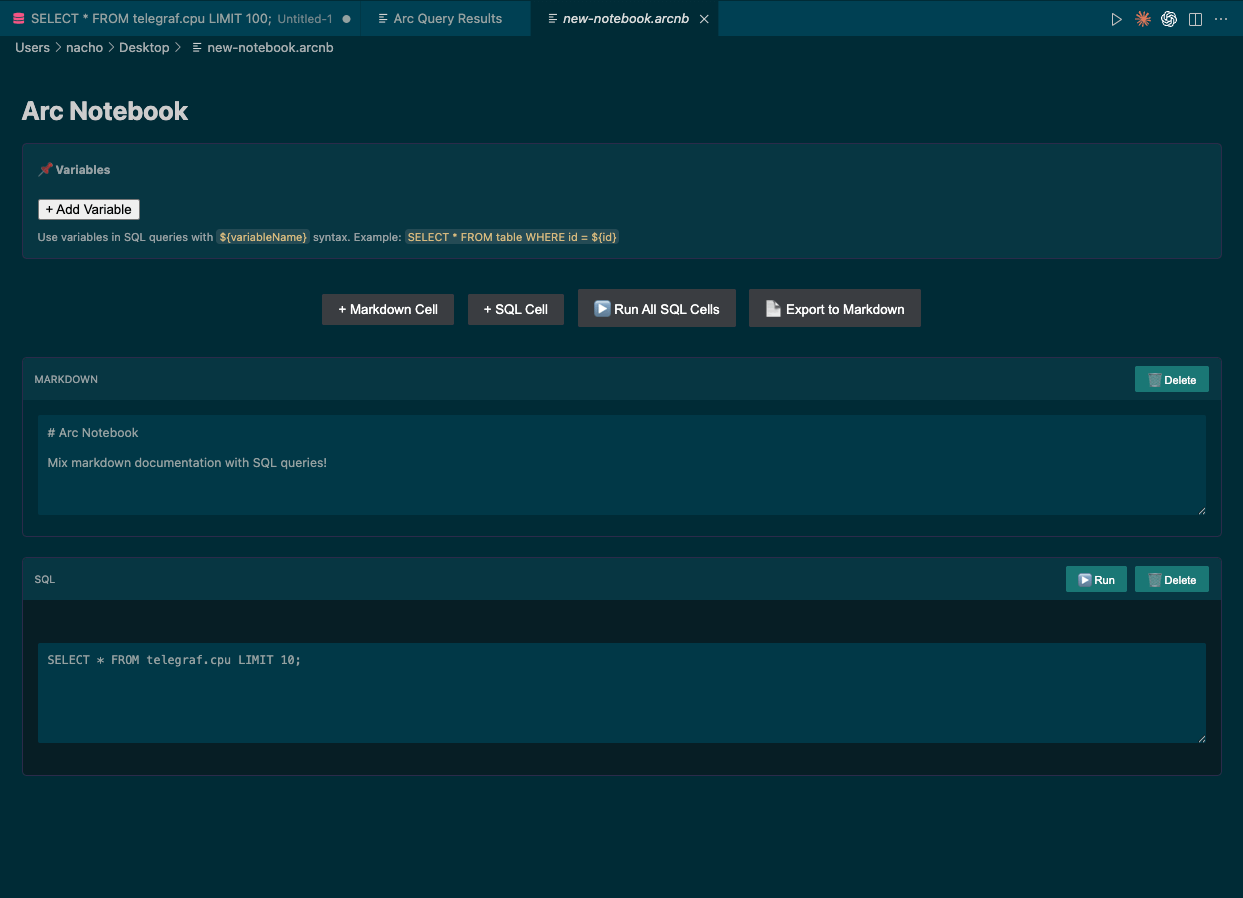
From here the floor is yours. Arc makes it easy to pull data from different databases into a single view. Imagine logs and system utilization side by side in the same notebook to correlate issues in real time. Powerful.
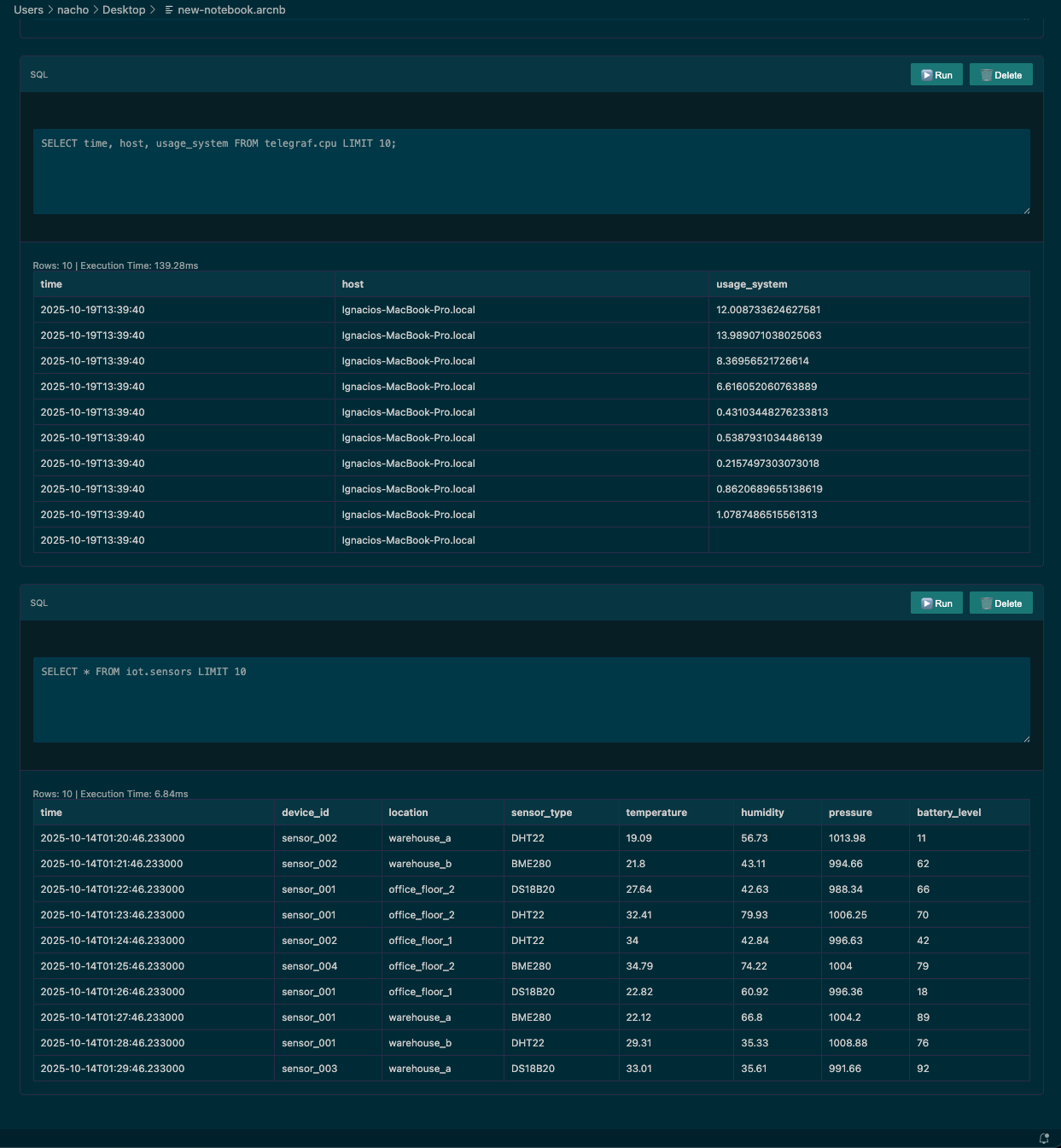
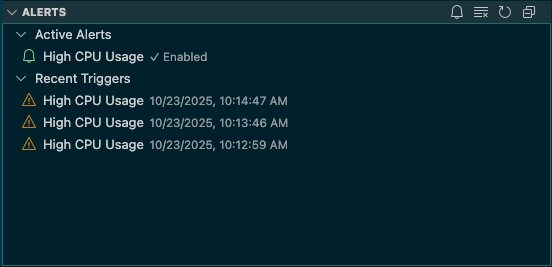
Alerts
Alerts are one of my favorite features because they surface outliers instantly.
I set up a quick check on CPU usage. Click Active Alerts, give the alert a name, add your query (mine was select usage_system from telegraf.cpu), set the threshold, and choose how often it should run. I went with a 60-second interval.
High CPU Usage
Query: select usage_system from telegraf.cpu
Condition: greater than 0
Check Interval: 60s
Status: Enabled
Last Check: 10/23/2025, 10:12:59 AM
Last Result: 12.008733624627581
Triggered: 1 time
When the alert fires you'll see a notification like this—pretty handy, right?
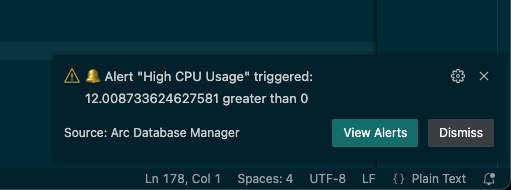
You can review alert history in the same panel and dive into what triggered each event.
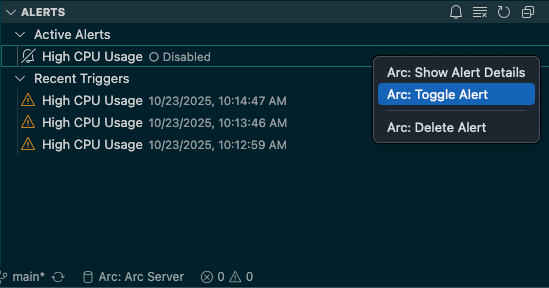
Disabling an alert when you're done takes just a couple of clicks.
To conclude
This walkthrough only scratches the surface of what the Visual Studio Code extension for Arc can do. We're continuing to improve it so working with Arc feels effortless for both administrators and engineers.
Want to collaborate? The project is open source:
github.comBasekick-Labs/arc-vscode-extensionhttps://github.com/Basekick-Labs/arc-vscode-extension
You'll find full instructions, examples, and release notes in the Marketplace listing:
And of course, here's the Arc repo itself—can't wait to see what you build with it.
github.comBasekick-Labs/archttps://github.com/Basekick-Labs/arc
Until next time.