Outrunning the Giants: How Arc Became the Fastest Time-Series Engine on ClickBench
It's been crazy the last two weeks since we released the code of Arc Core (OSS) on GitHub on October 7. But as you read in the first blog post, Arc is a project that's been in the works for 3 years, and now, with the release of the code, we felt ready to compare Arc against the giants of the time series industry.
And the way we did that was using ClickBench, a benchmark tool widely recognized in the industry to prove the speed of the systems being tested.
Before going into the actual numbers, let me share what I feel about benchmarks—they're a vanity metric, something you can claim, but in reality there aren't many use cases that need, for example, 2.42M RPS. Based on my experience, I've only found a very small number of corporations, like streaming ones, that ingest around that.
But also, that doesn't mean that because only a small number of projects need that level of performance, the software should be slow or not take performance into consideration. Also think that competition elevates us, makes us better, and in that sense it's clear we enjoy these results, but also, they set the north star to chase the improvements we need to make.
That said, let me introduce you to the numbers that show Arc is not only the fastest time series database/data warehouse, but also, thanks to the decision to use DuckDB as our SQL engine, we're in the top 8 fastest systems out there.
Arc is the fastest time series database/data warehouse
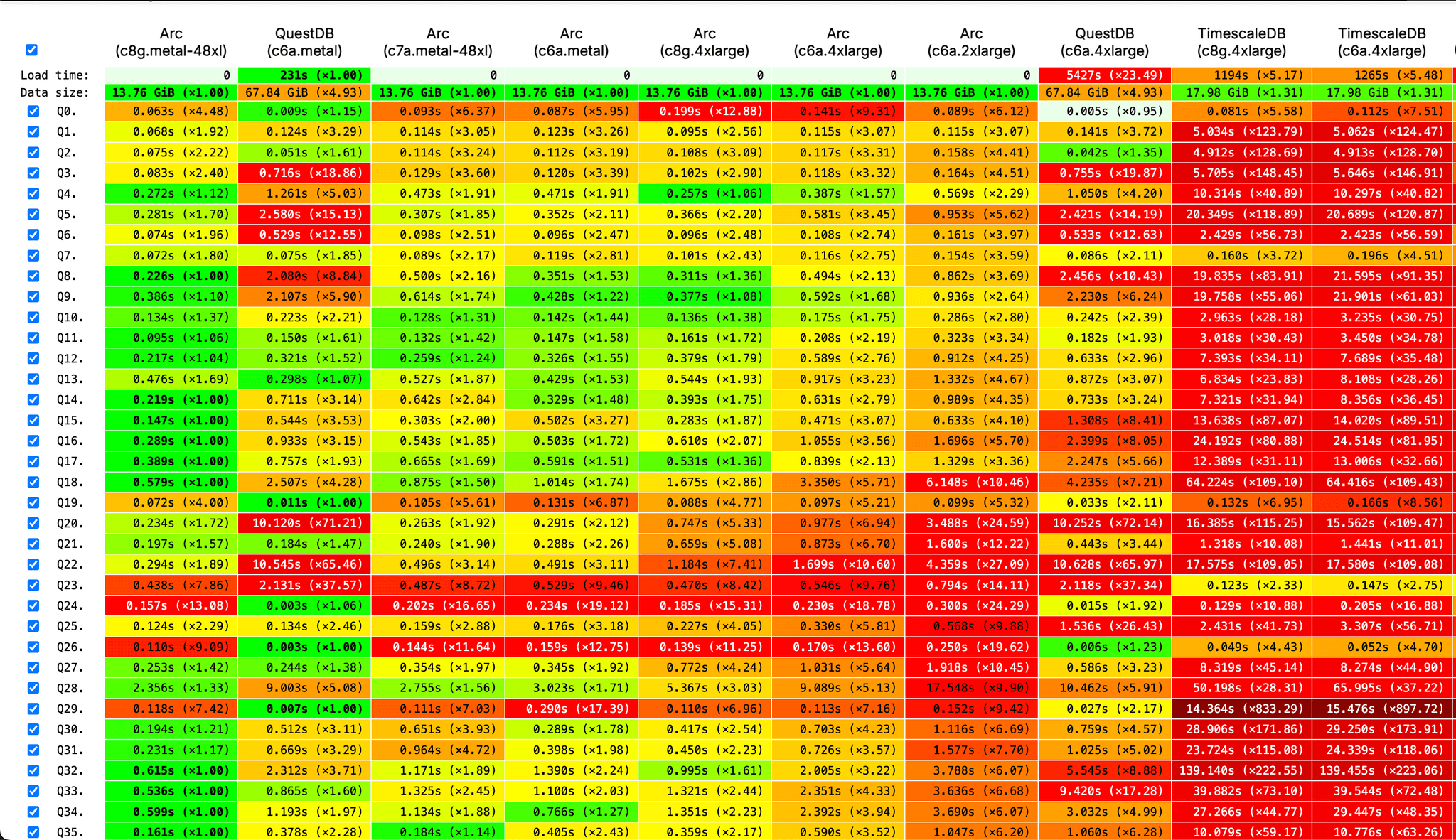
Let me start with a graph that shows how we perform in c6a.4xlarge (combined), which is the standard for ClickBench. We outperform QuestDB (they're doing a great job) and TimescaleDB in Combined. In Cold, we win too. In Hot, QuestDB takes the lead there—looks like their caching is very aggressive.
You can see the current values yourself on the ClickBench site
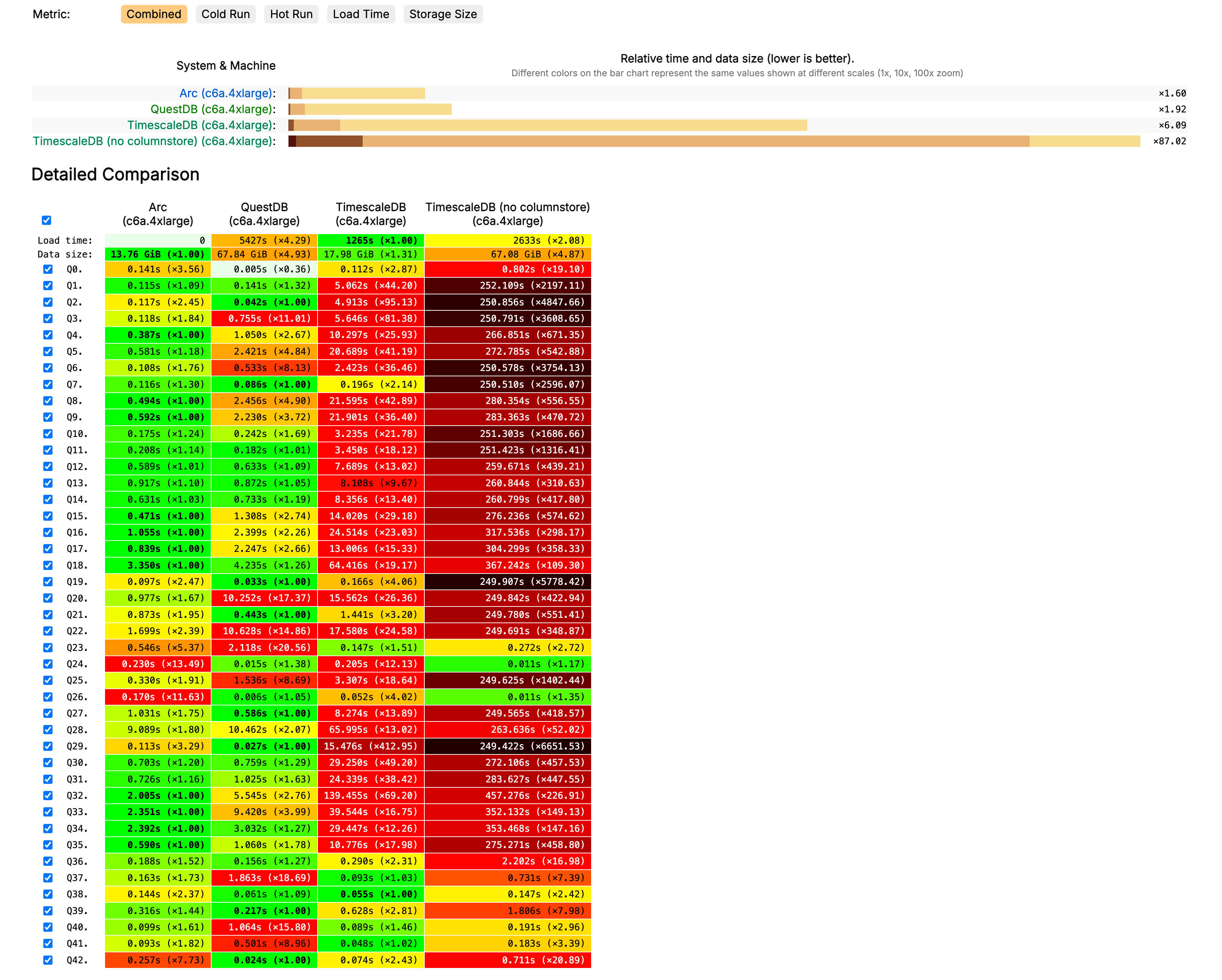
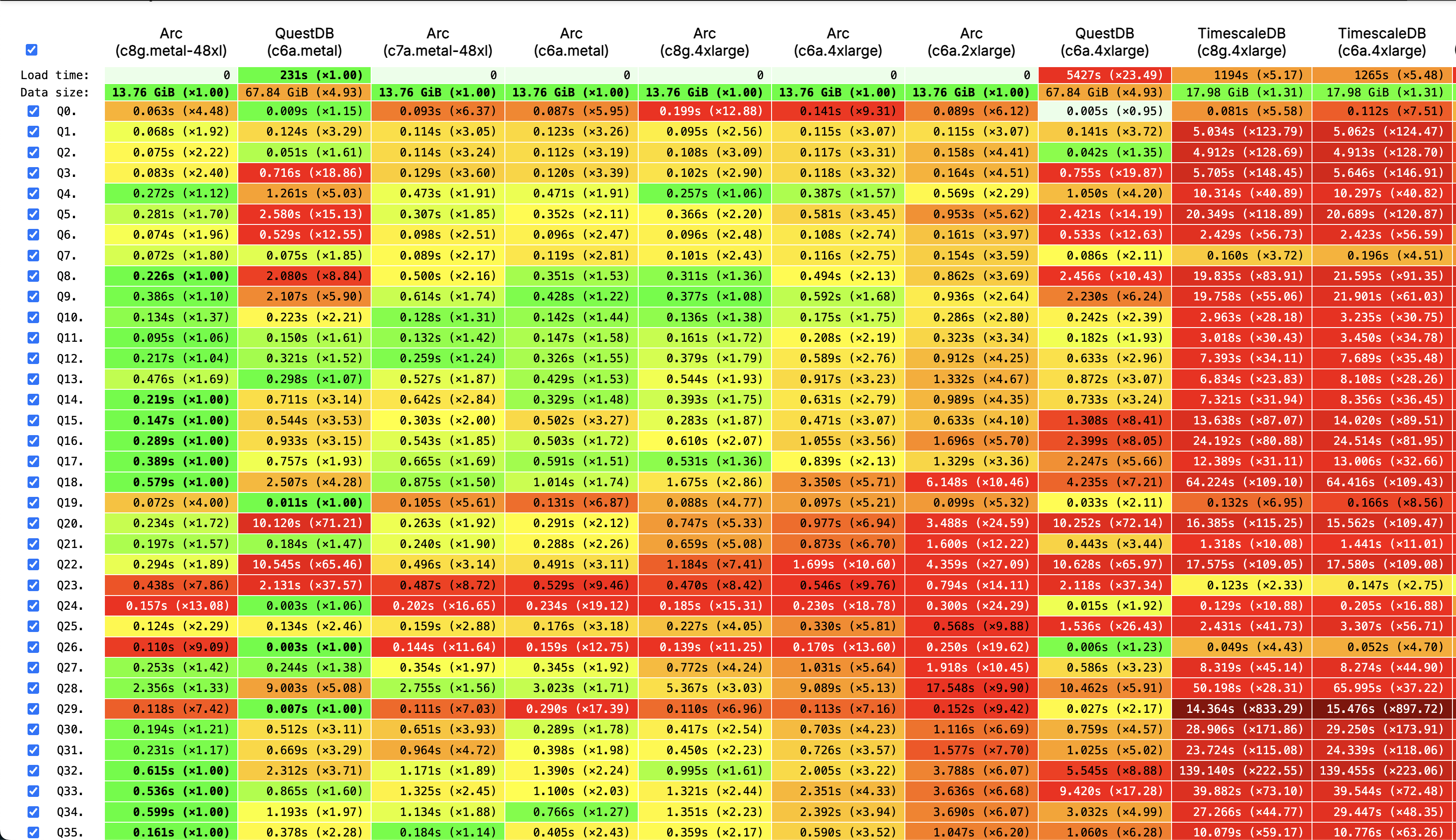
Now, if we look at all the system sizes, we outperform in every one of them in Cold Run, except in c6a.metal where QuestDB is doing a great job.
Here's a screenshot of those results, but if you want to see the full results and dive into the specific queries, you can click here
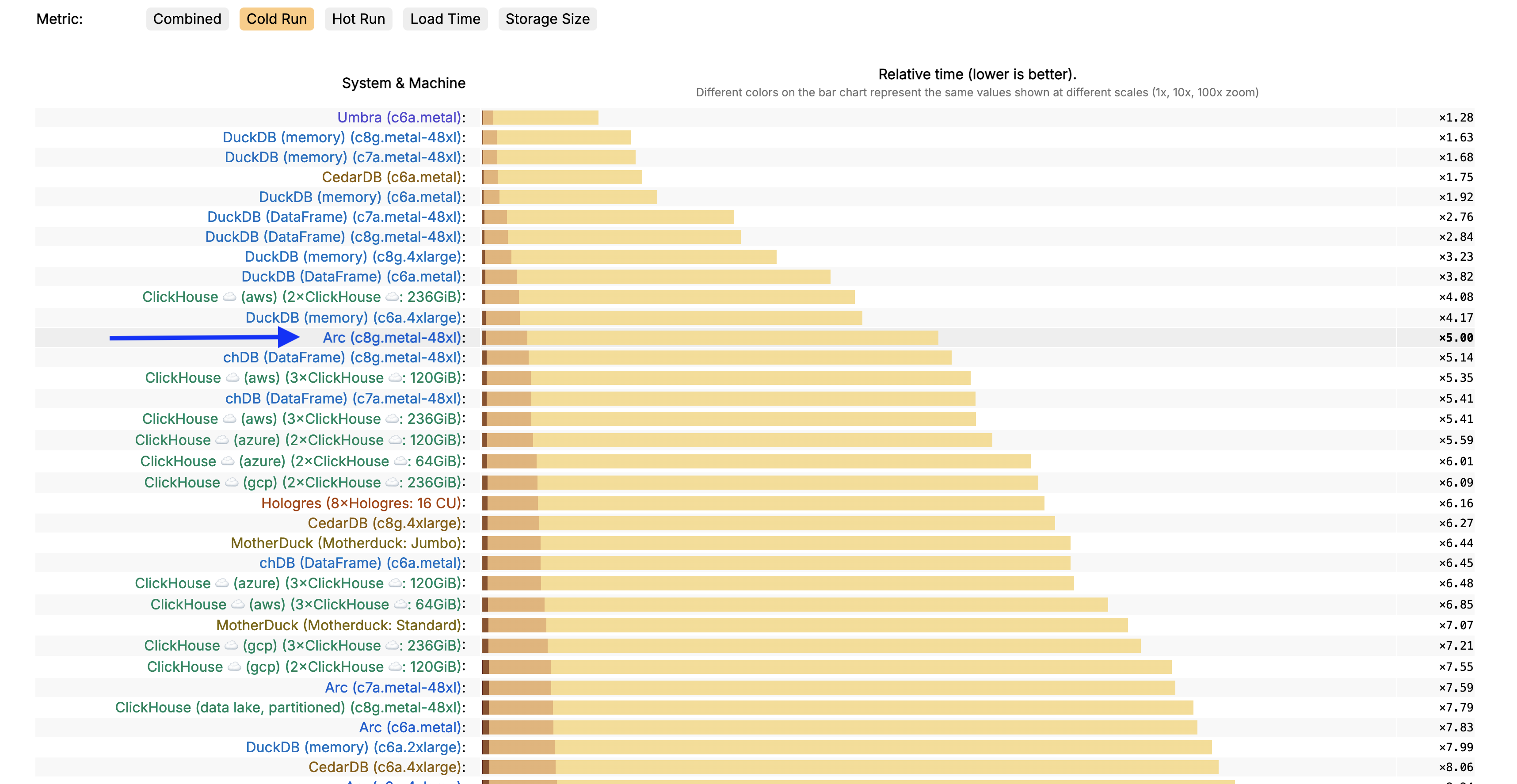
What about comparing to other systems?
Well, Arc does an excellent job there too, because if we look at the entire zoo of systems out there, Arc is one of the fastest systems. We're only behind a few monsters in the industry: DuckDB, ClickHouse, and CedarDB.
Ok, we got it, you are doing pretty well, what's the secret?
Something that gives us an advantage is the design decisions we made when we started building Arc, we didn't try to reinvent the wheel, we built on the shoulders of DuckDB, which we chose as our SQL engine.
But also, we chose MessagePack, which offers incredible performance, and if we combine that with zero-copy passthrough with the columnar format of Parquet that are part of the core of Arc, it allows us to process 2.42M requests per second. It's kind of the same at the query level—we use Apache Arrow, again, in the same way, zero-copy in columnar format so you get your data blazing fast.
In the middle, we implemented our own set of procedures to avoid locking the system and to do proper multi-threading in a bunch of processes, like compaction or WAL, to offer data durability with just a little bit of overhead.
This is just the beginning and we're just starting, with the premise of offering something really performant that can scale and isn't a monster (right now Arc is approximately 5,500 lines of code).
What can you build with Arc?
Now, beyond the numbers, let me share what this performance means for real-world applications. Arc's speed isn't just about bragging rights—it's about unlocking use cases that were previously challenging or expensive to implement.
IoT and Smart Devices: Imagine you're managing millions of sensors sending data every second. With Arc's 2.42M RPS ingestion capability, you can handle massive IoT deployments without breaking a sweat. Whether it's smart cities, industrial sensors, or connected vehicles, Arc can ingest, store, and query your telemetry data in real-time without requiring a massive infrastructure investment.
Logistics and Supply Chain: Track your entire fleet, warehouse operations, or shipment movements with millisecond-level precision. Arc's query speed means you can run complex analytics on location data, delivery times, and route optimization in real-time, helping you make decisions faster and keep your operations running smoothly.
Aerospace and Aviation: When you're dealing with flight data, aircraft telemetry, or air traffic patterns, speed and reliability aren't optional. Arc can handle high-frequency aircraft sensor data, ground station telemetry, and flight operations analytics while giving you instant query responses for safety-critical decision-making.
Observability and Monitoring: If you're running modern cloud infrastructure, you know that observability data can quickly become overwhelming. Arc excels at ingesting metrics, logs, and traces at scale. The zero-copy columnar format means you can query across billions of data points to troubleshoot issues, analyze system performance, or detect anomalies without waiting around.
Financial Services and Trading: Market data, transaction logs, and trading signals generate massive time-series datasets. Arc's sub-millisecond query performance means you can run real-time analytics on market trends, backtest trading strategies, or monitor risk across your entire portfolio without compromise.
The key advantage? You get all this performance without the operational complexity. Arc's small footprint (5,500 lines of code) means fewer moving parts, easier debugging, and a system you can actually understand and maintain.
In the future
As I said, this is just the beginning and we're pumped to keep shipping features that will allow Arc to not only be the most performant, but the go-to option for time series/analytics use cases. The community has been responding—as of the time I'm writing this, we have 252 stars on GitHub in only 13 days since the Arc Core repo went live.
We've already answered more than 100 emails and comments all over the place asking about Arc, how it works, and what our plans are (roadmap coming soon).
We're sure we want to keep pushing in this direction, keep talking with the communities and potential new partners to shape Arc into something that solves your issues.
Get started with Arc
Ready to try the fastest time series database? Here's how to get started:
Check out the Arc Core repository on GitHub and star it if you find it interesting:
github.comBasekick-Labs/archttps://github.com/Basekick-Labs/arc
Join our growing community, ask questions, share your use cases, or contribute to the project. We're actively responding to issues, discussions, and are excited to hear what you're building.
Again, this is just the beginning. Thank you for the love we're getting, and don't forget to stay tuned to this blog to get news about Basekick Labs and Arc, the fastest time series database.
Build your next observability platform with Arc
Deploy in minutes with Docker or native mode. Ingest millions of metrics per second, query millions of rows in seconds, and scale from edge to cloud.