Hello World, We are Basekick Labs and We Bring Arc to the Game

Welcome to Basekick Labs, where we're building Arc. But what is Arc?
Arc is a high-performance time-series data warehouse for engineers building observability platforms, IoT systems, and real-time analytics. It's built on DuckDB and Parquet with 2.01M records/sec ingestion, SQL analytics, and flexible storage options for unlimited scale. Most importantly, Arc is the fastest time-series database.
But wait—where did all this start? How did we get here? Those are great questions, and we're going to answer them by telling you a story.
Where It All Started
To understand where we came from, we need to go back to November 2022. While working in the time-series database industry, I bought a separate computer for personal side projects—something I could keep independent for after-hours work. In my spare time, I started building an API that could automate the deployment of various time-series tools across different cloud providers. The idea was to create an API-first platform that offered hosted and managed versions of these technologies.
I worked on that until June 2023, when I decided to pursue this idea full-time. At that moment, I was focused on providing technical coverage in Latin America for time-series software, with a heavy focus on IoT use cases.
We had some customers, but as we evolved the platform to integrate more cloud providers, I knew I needed to work on something we owned. A database? Maybe. But the core idea was simple: stop depending on others to build our business. Eventually, I wanted to migrate customers we were hosting on InfluxDB, TimescaleDB, QuestDB, and other databases to something we controlled end-to-end.
I created a pilot called Wavestream. It was very primitive, offering about 20k writes per second on 8 cores and 16GB of RAM. At that point, it was clear I had a lot of work to do.
That venture ended in 2024, and I started analyzing how I could keep moving forward. I recalled the Wavestream idea, but the code was gone. For me, it was attached to negative moments. If I was going to start something new, it needed to be 100% fresh.
The Birth of Historian (and Eventually Arc)
So I started again. I built something that, one year later in 2025, I called Historian. The platform was created to offer tiered storage for InfluxDB v1.x and 2.x, with eventual support for other databases. The key innovation was storing data in Parquet files on S3.
That worked well. I was able to sell this to specific InfluxDB Enterprise customers who were experiencing scaling issues.
During the development of Historian, I included DuckDB as the engine for running SQL queries on Parquet files. I introduced time-based indexing. And one step at a time, Historian was converting from an archive solution into something much bigger.
So, Today?
Today, that bigger thing is Arc. As I stated earlier, Arc is a time-series data warehouse built for speed, with a record of 2.01M records/sec on local NVMe in a single node. It combines DuckDB, Parquet, and flexible storage (local/MinIO/S3/GCS).
More importantly, Arc is the fastest time-series database, with a cold run time of 36.43 seconds on 99.9 million rows, beating VictoriaLogs (3.3x), QuestDB (6.5x), Timescale Cloud (18.2x), and TimescaleDB (29.7x).
The core version is published on GitHub under the AGPL-3.0 license. We believe in open formats, transparent benchmarks, and building tools that engineers actually want to use.
Arc's Key Features
Here are some of Arc's standout features:
- High-Performance Ingestion: MessagePack binary protocol (recommended), InfluxDB Line Protocol (drop-in replacement), JSON
- Multi-Database Architecture: Organize data by environment, tenant, or application with database namespaces
- Write-Ahead Log (WAL): Optional durability feature for zero data loss (disabled by default)
- Automatic File Compaction: Merges small Parquet files into larger ones for 10-50x faster queries (enabled by default)
- DuckDB Query Engine: Fast analytical queries with SQL, cross-database joins, and advanced analytics
- Flexible Storage Options: Local filesystem (fastest), MinIO (distributed), AWS S3/R2 (cloud), or Google Cloud Storage
- Data Import: Import data from InfluxDB, TimescaleDB, HTTP endpoints
- Query Caching: Configurable result caching for improved performance
The Response Has Been Incredible
But this is just the beginning. After six days of publishing the code, the response has been amazing. We hit over 200 stars on GitHub, and I've spent most of the last five or six days responding to questions on Reddit, Hacker News, email, and even Russian blogs that noticed Arc and called us "the ClickHouse killer", something I don't believe for a minute. ClickHouse is a great tool, and while we're doing well, we're focused on the time-series category specifically.
Here's our GitHub star growth:
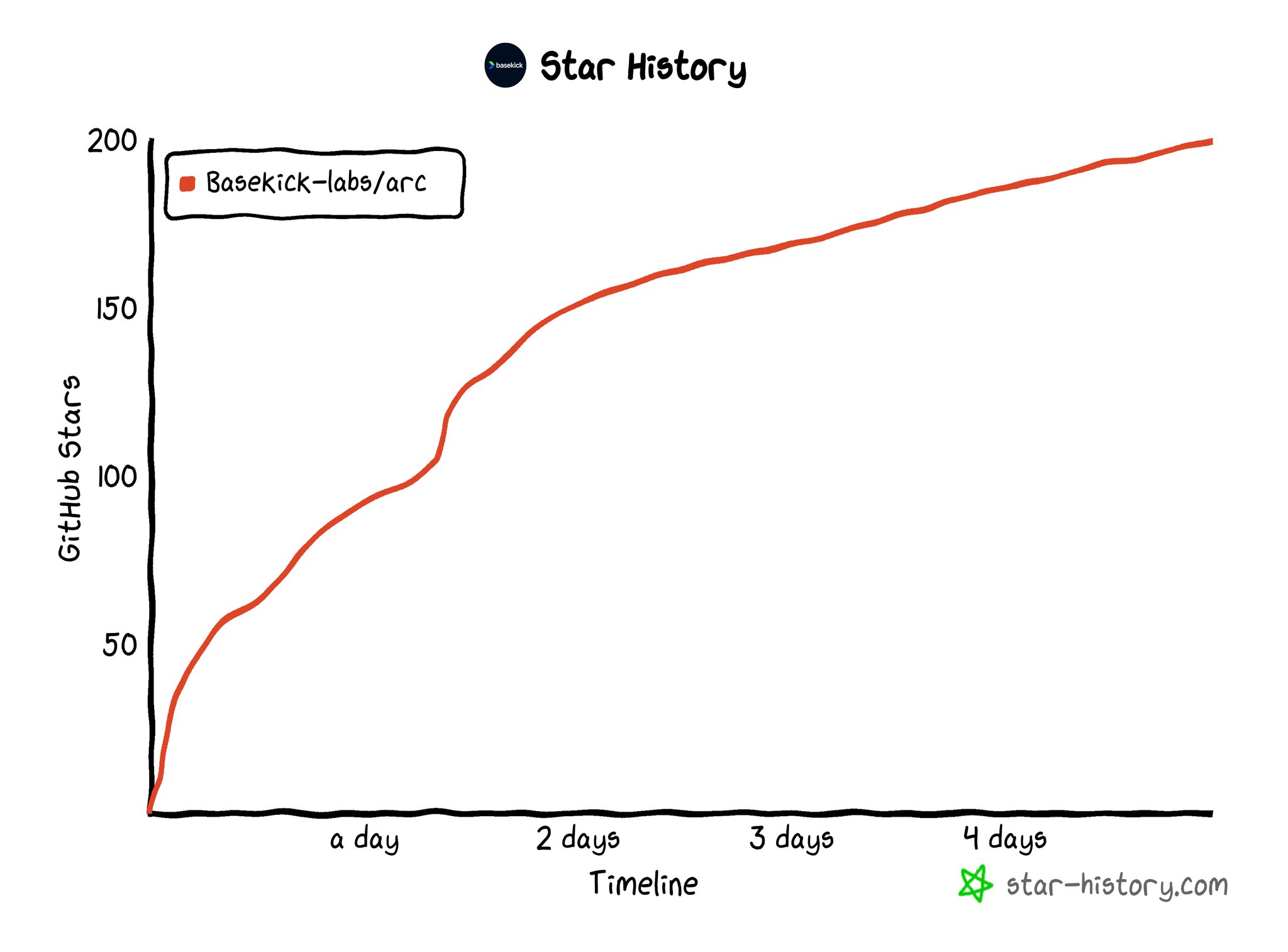
We've also already built an integration to connect Apache Superset to Arc, and we're working to get that documented on the Superset documentation website. Over the weekend, we also started building an output plugin for Telegraf, the collector from InfluxData.
Why Are We Here?
That's a great question. We're here to offer a modern and performant time-series technology that doesn't change engines with every version, doesn't confuse people with too many versions, isn't mounted over another database, and isn't pivoting to logs because they're trying to kill Datadog.
We're here for the engineers.
We're here for those who need to collect data from the edge to understand how their trucks are performing and where they are. We're here to give insights to doctors about the health of their patients. We're here to empower teams developing solutions that clean CO2 from the environment. We're here for platform engineers who need to understand how their infrastructure performs.
And with Arc Core, we're here to help students and hobbyists monitor their grills, plants, track planes, vessels, and more.
This Is Just the Start
We're incredibly excited about what we're building, and we want you to test it. Let us know the good, but especially the bad. Over the weekend, we learned about several issues that helped us improve from 1.95M RPS to 2.01M RPS. That's what open source is all about—it's not just code, it's feedback too.
Check out Arc on GitHub:
github.comBasekick-Labs/archttps://github.com/Basekick-Labs/arc
Welcome to Basekick Labs. Welcome to Arc. Let's make history.
Build your next observability platform with Arc
Deploy in minutes with Docker or native mode. Ingest millions of metrics per second, query millions of rows in seconds, and scale from edge to cloud.